
What I shipped today in TokenGolf v0.4.0


By the end of Sunday, TokenGolf felt real in the way a lot of early projects don't.
The score was believable. The product lived inside the session instead of next to it. The game had real pressure and some strategic texture. That's a meaningful threshold.
It still wasn't enough.
There was a lot of behavioral truth already sitting in the run data that the system wasn't naming. And once a game starts building out a rule surface like this, "I think it still works" stops being a responsible release strategy pretty quickly.
So Monday became two things at once: expansion and hardening.
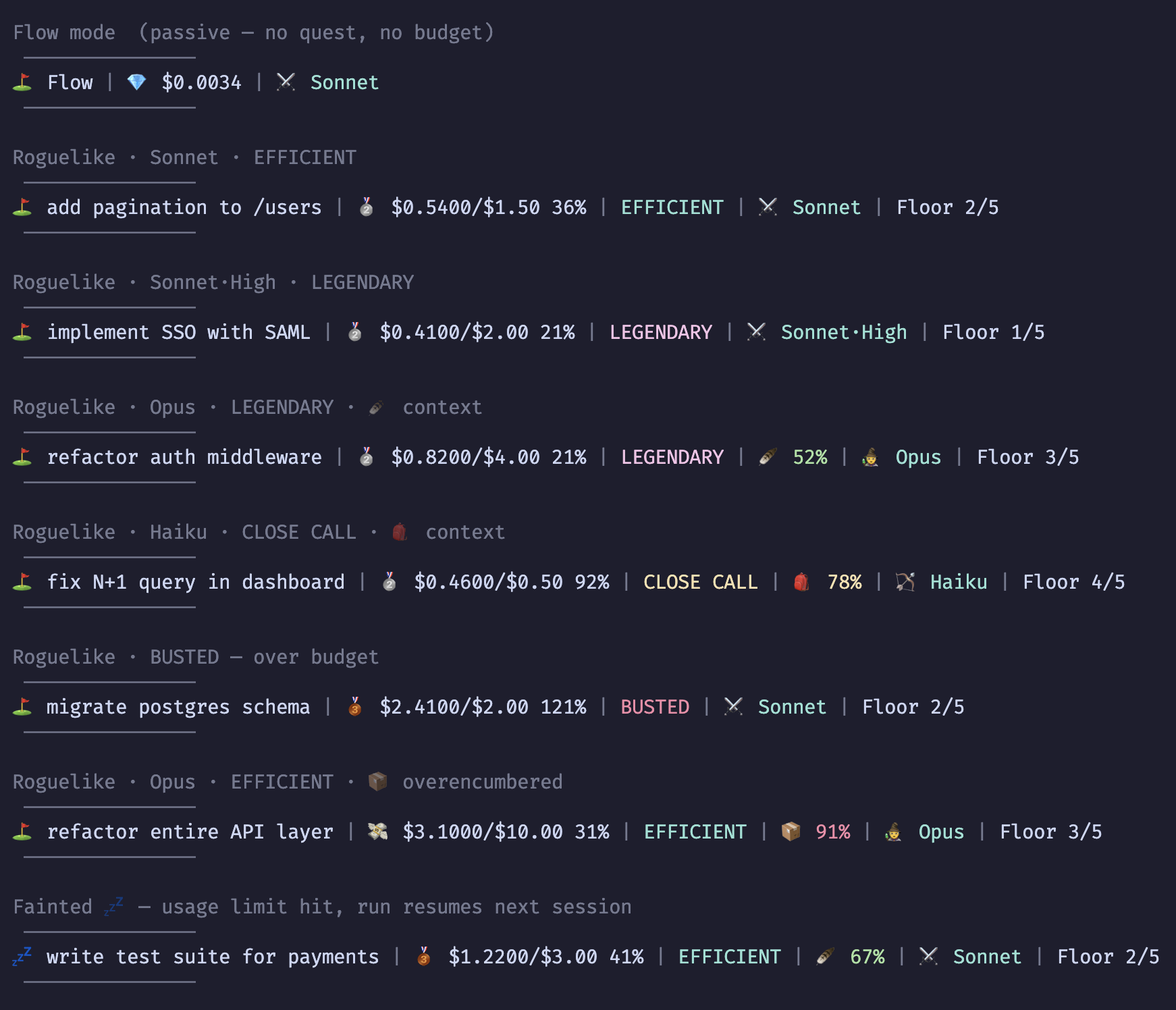
The achievement expansion started from the right question
The bad version of achievement design is badge soup. Random trophies with no relationship to the underlying system. That was never the goal. The useful question was simpler: what are we already observing that the game still isn't acknowledging?
That immediately opened up more interesting territory.
Prompt count had been there already. But raw prompt count alone doesn't tell you much. The game wasn't yet distinguishing between perfectly front-loaded clarity, strong delegation, meandering conversation, or constant mid-course correction. Those are different behaviors. They burn cost differently. They reflect different levels of skill or confidence.
So prompting style became part of the score.
One Shot, Conversationalist, Terse, Backseat Driver, High Leverage.
Those aren't just cute names. They're there to capture that the same task can be approached in very different ways, and those ways matter. A session where you say very little and Claude does a lot feels different from a session where you keep reaching into the loop every few turns. Now the game can tell the difference too.
// src/lib/score.js — prompting skill achievement conditions
if (promptCount === 1)
achievements.push({
key: "one_shot",
label: "One Shot — Completed in a single prompt",
emoji: "🥊",
})
if (promptCount <= 3 && totalToolCalls >= 10)
achievements.push({
key: "terse",
label: `Terse — ${promptCount} prompts, ${totalToolCalls} tool calls`,
emoji: "🤐",
})
if (promptCount >= 2 && totalToolCalls / promptCount >= 5)
achievements.push({
key: "high_leverage",
label: `High Leverage — ${(totalToolCalls / promptCount).toFixed(1)}× tools per prompt`,
emoji: "🏗️",
})Tool use and ratios made working style visible
Tool usage had a similar problem.
"Used tools" is not a play style. But read-heavy runs, shell-heavy runs, tightly scoped edit runs, and broad-spectrum exploratory runs are. So tool-mastery achievements started naming those patterns instead of flattening them into one bucket.
Read Only, Surgeon, Scout, Bash Warrior, Editor, Toolbox.
The ratio-based stuff got more interesting too.
Raw spend is useful, but it's not the whole story. Spend per prompt tells you whether each exchange is cheap and focused or expensive and heavy. Turn count relative to prompt count says something about how much autonomy Claude actually had in the loop. Failed tool calls tell a very different story from successful ones, because failures are not free. They cost tokens too. They also shift the whole shape of a run from execution toward recovery.
So that's where cost-per-prompt, turn-discipline, reliability achievements, and the expanded death marks came from.
Cheap Shots, Expensive Taste, Agentic, Obedient, Clean Run, Stubborn, Blowout, So Close, Tool Happy, Silent Death, Fumble.
// Tool: Bash Warrior — shell-heavy run
if (bashCount >= 10 && bashCount / totalToolCalls >= 0.5)
achievements.push({
key: "bash_warrior",
label: `Bash Warrior — ${bashCount} Bash calls`,
emoji: "🐚",
})
// Ratio: Agentic — Claude doing multiple turns per prompt
if (promptCount >= 2 && turnCount >= 1 && turnCount / promptCount >= 3)
achievements.push({
key: "agentic",
label: `Agentic — ${(turnCount / promptCount).toFixed(1)} turns per prompt`,
emoji: "🤖",
})
// Death mark: Fumble — failed tool calls on a died run
if (!won && (run.failedToolCalls ?? 0) >= 5)
achievements.push({
key: "fumble",
label: `Fumble — Died with ${run.failedToolCalls} failed tool calls`,
emoji: "🤡",
})Small hooks unlocked a lot more behavior
Those categories only needed a few extra tracking fields to become real.
That was another useful lesson in this project. Small instrumentation changes can unlock much richer semantic territory than you'd expect.
That's what the new hooks were really for.
PostToolUseFailure let the run track failed tool calls. SubagentStart made subagent spawns visible. Stop added turn count. None of those hooks are huge by themselves. But once those counters exist, the game can see a lot more of how the run actually unfolded.
There was also one class-level change that felt right by this point.
Opus had started to have more than one meaningful play style. There's the raw expensive-power version, and then there's the more deliberate plan-mode posture. Those don't feel identical in practice, even if they sit on the same underlying model economics. So Paladin became a real class identity for Opus in plan mode. Same model family, different posture. More deliberate. More structured.
// Three hooks — identical structure, each incrementing one counter in current-run.json
// hooks/post-tool-use-failure.js → failedToolCalls
// hooks/subagent-start.js → subagentSpawns
// hooks/stop.js → turnCount
process.stdin.on("end", () => {
try {
const run = JSON.parse(fs.readFileSync(STATE_FILE, "utf8"))
if (!run || run.status !== "active") process.exit(0)
const updated = { ...run, failedToolCalls: (run.failedToolCalls || 0) + 1 }
// ^ swap for subagentSpawns or turnCount in the other two
fs.writeFileSync(STATE_FILE, JSON.stringify(updated, null, 2))
} catch {}
process.exit(0)
})The rules got dense enough to need protection
By then the scoring system had enough moving parts that hardening stopped being optional.
That's where the test suite became part of the release story, not just cleanup work. Once calculateAchievements() starts carrying this many edge cases and exceptions, regressions get quiet. They don't usually explode. They just quietly make the game tell the wrong story about a run. That's worse.
So the project got a real Vitest suite across the rule surface. Positive cases, negative cases, null budgets, missing optional fields, death-mark isolation, the whole thing. That's the moment where the project admits to itself that intuition is no longer enough.
The same logic applied to the surrounding tooling.
A release like this can't just rely on vibes. If formatting drifts, lint breaks, the build goes stale, tests stop running, or the core context file gets out of sync with the actual system, the project starts rotting in subtle ways.
So today also became the day of release guardrails.
Husky pre-commit. ESLint. Prettier. The CLAUDE.md consistency pass. Tighten the project context so future work doesn't inherit confusion. Make the path to shipping stricter than "I think it's fine."
// src/lib/__tests__/score.test.js — frugal + rogue_run test block
describe("frugal + rogue_run", () => {
it("frugal: haiku ≥50% of spend", () => {
const mb = { "claude-haiku-4-5-20251001": 0.06, "claude-sonnet-4-6": 0.04 }
expect(keys(wonRun({ modelBreakdown: mb, spent: 0.1 }))).toContain("frugal")
})
it("rogue_run: haiku ≥75% of spend", () => {
const mb = { "claude-haiku-4-5-20251001": 0.08, "claude-sonnet-4-6": 0.02 }
expect(keys(wonRun({ modelBreakdown: mb, spent: 0.1 }))).toContain(
"rogue_run"
)
})
it("no frugal when haiku < 50%", () => {
const mb = { "claude-haiku-4-5-20251001": 0.04, "claude-sonnet-4-6": 0.06 }
expect(keys(wonRun({ modelBreakdown: mb, spent: 0.1 }))).not.toContain(
"frugal"
)
})
it("no rogue_run when haiku < 75%", () => {
const mb = { "claude-haiku-4-5-20251001": 0.06, "claude-sonnet-4-6": 0.04 }
expect(keys(wonRun({ modelBreakdown: mb, spent: 0.1 }))).not.toContain(
"rogue_run"
)
})
})Why this is v0.4.0
That kind of work is easy to underrate because it doesn't show up in a screenshot. But it's part of what separates an entertaining prototype from something you can push out without holding your breath.
And that's really what today was about.
On the surface, this looks like a day of expansion and polish. More achievements. More hooks. More structure. More tooling. That's all true.
But the deeper thing is that TokenGolf got more expressive and more defensible at the same time.
It can now describe more of how people actually use Claude Code. Not just whether they won, but how they prompted, how they delegated, how they failed, how they recovered, how they burned, how they stayed disciplined, how they spread work across subagents, how they handled the shell, how they managed turn depth.
And it has more of the release infrastructure it needs so those rules don't drift every time the code changes.
That's why this feels like the right moment to call it v0.4.0.
Not because it's done. It isn't. Projects like this get more interesting once other people start touching them and exposing the edges you were too close to see.
But it's real now in a way it wasn't a few days ago.
That's the part I care about.
TokenGolf is still a Node CLI at heart, built with Commander, Ink, React, and @inkjs/ui, bundled with esbuild, and now guarded by Vitest, ESLint, Prettier, and Husky. That stack isn't the story by itself. But it matters because the product got better once the implementation stopped faking completeness and started earning trust.
AI coding already felt like a run
TokenGolf still looks like a joke project at first glance. A roguelike wrapper for Claude Code is obviously funny. That's part of why I liked the concept in the first place.
But it keeps getting stronger because the underlying model is true.
AI coding already feels like a run.
There's pacing. There's delegation. There's greed. There's overthinking. There's cheap wins, expensive mistakes, context pressure, recoveries, blowouts, near-misses, stupid deaths, disciplined clears.
TokenGolf just says that out loud, then gives it rules.
Building TokenGolf is an ongoing series about turning Claude Code sessions into a roguelike. You can see the product, try it, and follow along at https://josheche.github.io/tokengolf/
Related Posts
The wizard asked you to commit a budget before you knew what the session needed. Par replaced that question with a better one: how efficient were you given what actually happened?
By the end of Saturday, the score was believable. Sunday became the day of friction removal and deeper integration.
Saturday was where TokenGolf stopped being a neat concept and started becoming a real tool. The first milestone had nothing to do with the game.